Projet de machine learning
J'ai commencé par analyser la dispersion des données, remarquant une sous-représentation significative de certaines catégories. Pour corriger ce déséquilibre, j'ai décidé d'employer une technique de suréchantillonnage, assurant ainsi une meilleure représentativité dans notre jeu de données. Je n'ai d'ailleur pas opté pour une classification linéaire dans ce projet Kaggle car les données présentaient une complexité et des interactions non linéaires entre les variables qui ne pouvaient être adéquatement capturées par un modèle linéaire
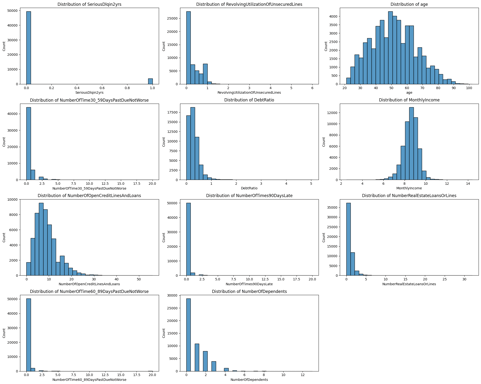
Découverte du dataframe
J'ai utilisé quatre modèles de type arbre : Bagging, Random Tree, AdaBoost, et un arbre de décision "classique". Bien que chaque modèle ait présenté de bonnes performances, j'ai observé de légers écarts entre les résultats de test et d'entraînement. Ces écarts, bien que faibles, suggéraient des niveaux variés de surajustement ou d'ajustement insuffisant selon le modèle.
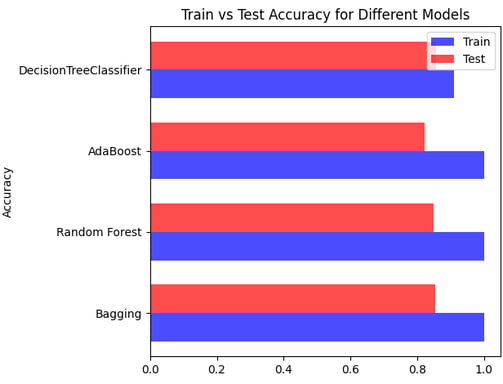
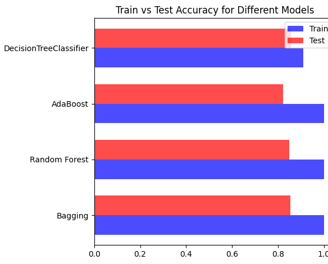
Les arbres de décision
Ayant observé des écarts entre les données de test et d'entraînement dans les quatre modèles de tree utilisés (Bagging, Random Tree, AdaBoost, et arbre de décision classique), j'ai donc décidé d'utiliser les courbes ROC (Receiver Operating Characteristic) pour affiner mon choix de modèle. Les courbes ROC, en illustrant le taux de vrais positifs par rapport au taux de faux positifs à différents seuils de classification, m'ont permis d'évaluer plus précisément la performance de chaque modèle.
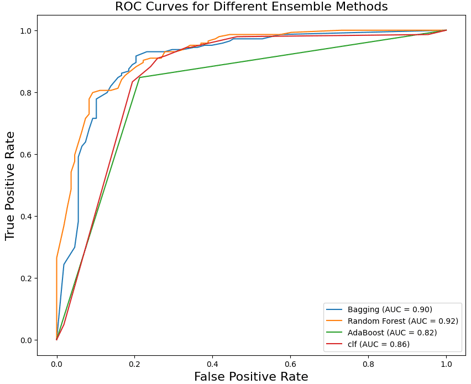
Etude des résultats
Ayant encore du temps durant la compétition, j'ai utilisé un réseau de neurones conçu avec TensorFlow Keras, composé de trois couches. La première couche, avec 32 neurones et une fonction d'activation 'relu', sert à capturer les relations non linéaires entre les variables. La seconde couche, plus petite avec 8 neurones, continue ce traitement en réduisant la dimensionnalité, tout en conservant les caractéristiques importantes. Enfin, la troisième couche, avec un seul neurone et une fonction d'activation 'sigmoid', produit la sortie finale, classifiant les données en deux catégories. Ce réseau a été entraîné pour optimiser la classification binaire, utilisant la loss function binary crossentropy et mesurant l'accuracy comme métrique clé.
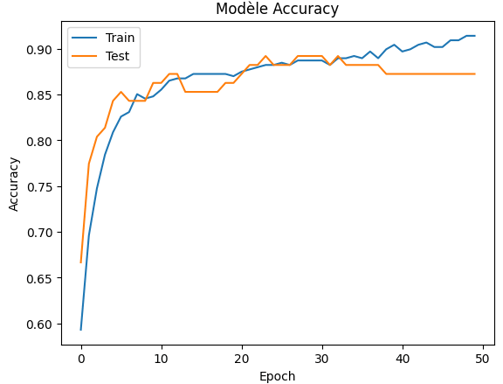
Réseau neuronal
Conclusion
Ce projet Kaggle a été une réussite, me permettant de décrocher la 3ème place dans la compétition. Il témoigne de l'efficacité de mon approche analytique et de ma capacité à appliquer des techniques de machine learning avancées. Pour ceux intéressés par une compréhension plus détaillée de mes méthodes et analyses, mon rapport complet est disponible ci-dessous, offrant un aperçu approfondi de mon travail et des stratégies qui ont mené à ce succès.